The “Real” Repository Pattern in Android
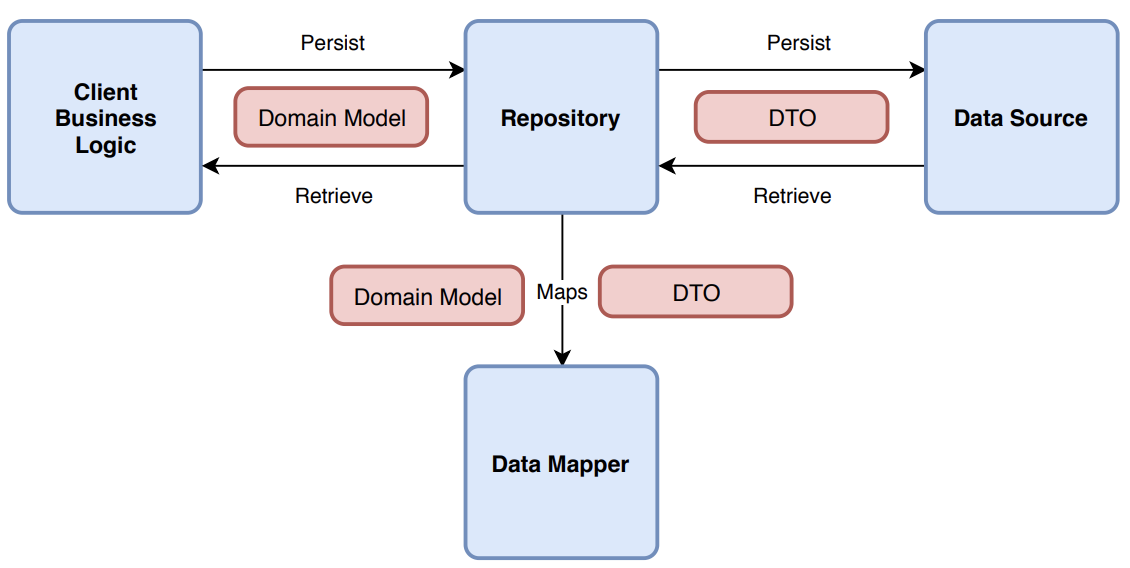
Over the years I’ve seen many implementations of the repository pattern, yet I think most of them are wrong and not beneficial.
These 5 are the most common mistakes I’ve seen (some of these are also in the official android documentation):
- The Repository returns a DTO instead of a Domain Model.
- DataSources (ApiServices, Daos..) use the same DTO.
- There is a Repository per set of endpoints and not per Entity (or Aggregate Root if you like DDD).
- The Repository caches the whole model, even those fields that need to be always up to date.
- A DataSource is used by more than one Repository.
That’s being said, how do we implement it right?android online training
You need a Domain Model
This is a key point of the Repository Pattern and I believe developers struggle in doing it properly because they don’t understand what the Domain is.
By quoting Martin Fowler we can say that a Domain Model is:
“An object model of the domain that incorporates both behavior and data.”
Domain models basically represent Enterprise-wide business rules.
For who is not familiar with Domain-Driven Design building blocks or with Layered architectures (Hexagonal, Onion, Clean…) there are 3 kinds of Domain Models:
- Entity: An entity is a plain object that has an identity (ID) and is potentially mutable.
- Value object: immutable object without identity.
- Aggregate root (DDD only): Entity that binds together with other entities (basically a cluster of associated objects).
In simple domains, these models will look very similar to the database and network models (DTOs), yet they still have lots of differences:
- Domain Models mingle data and processes, and their structure is the most suitable for the app.
- DTOs are the object model representation of a JSON/XML request/response or a database table, hence their structure is the most suitable for the remote communication.
Example of Domain Models:
//
Entity
data class Product(
val id: String,
val name: String,
val price: Price)
{
// Value object
data class Price(
val nowPrice: Double,
val wasPrice: Double )
{
companion object
{
val EMPTY = Price(0.0, 0.0)
} }}
Example of DTOs:
// Network DTO
data class NetworkProduct(
@SerializedName("id")
val id: String?,
@SerializedName("name")
val name: String?,
@SerializedName("nowPrice")
val nowPrice: Double?,
@SerializedName("wasPrice")
val wasPrice: Double?
)
// Database DTO
@Entity(tableName = "Product")
data class DBProduct(
@PrimaryKey
@ColumnInfo(name = "id")
val id: String,
@ColumnInfo(name = "name")
val name: String,
@ColumnInfo(name = "nowPrice")
val nowPrice: Double,
@ColumnInfo(name = "wasPrice")
val wasPrice: Double
)
As you can see the Domain Model is free from frameworks and its structure promotes multivalued attributes (logically grouped as you can see in Price) and uses the Null Object Pattern (fields are non-nullable), while DTOs are coupled with the framework (Gson, Room).
Thanks to this separation:
- the development of our app becomes easier since we don’t have to bother in checking null values and the multivalued attributes don’t force us to send the whole model around.
- changes in the data sources don’t affect our high-level policies.
- there is more separation of concerns since we avoid “god models”
- bad Backend implementations don’t affect our high-level policies (imagine if you are forced to perform 2 network requests because Backend is not able to give you all the information you need in a single one, would you let this issue affect your whole codebase?).
You need a Data Mapper
This is where we map DTOs into Domain Models and vice-versa.
Because most of the developers see this mapping as boring and unnecessary they prefer to couple their whole codebase, from the DataSources up to the UI, with DTOs.
While this makes (maybe) first releases faster to deliver, skipping the Domain Layer and coupling the UI with the DataSources produces several bugs that may be discovered only in production (i.e. BackEnd sending a null instead of an empty string which generates an NPE) other than hiding business rules and use cases in the presentation layer (i.e. Smart UI pattern).
In my opinion, mappers are fast to write and simple to test and even if their implementation is boring it makes sure we’ll never have surprises due to a change in the behavior of the DataSources.
If you don’t have time for mapping (or most probably don’t want to map) you can also rely on object mapping frameworks like http://modelmapper.org/ for speeding up this process.
Because I don’t like to use frameworks in my usual implementation, in order to remove some boilerplate code, I have a generic mapper interface for avoiding to create an interface for each mapping:
interface Mapper<I, O> {
fun map(input: I): O
}
And a set of generic ListMappers that avoid me to implement each specific List-to-List mapping:
// Non-nullable to Non-nullable
interface ListMapper<I, O>: Mapper<List<I>, List<O>>
class ListMapperImpl<I, O>
(
private val mapper: Mapper<I, O>
) : ListMapper<I, O>
{
override fun map(input: List<I>): List<O>
{
return input.map
{
mapper.map(it)
} }}
// Nullable to Non-nullable
interface NullableInputListMapper<I, O>: Mapper<List<I>?, List<O>>
class NullableInputListMapperImpl<I, O>( private val mapper: Mapper<I, O>)
: NullableInputListMapper<I, O>
{
override fun map(input: List<I>?): List<O>
{
return input?.map { mapper.map(it) }.orEmpty()
}}
// Non-nullable to Nullable
interface NullableOutputListMapper<I, O>: Mapper<List<I>, List<O>?>
class NullableOutputListMapperImpl<I, O>( private val mapper: Mapper<I, O>) : NullableOutputListMapper<I, O>
{ override fun map(input: List<I>): List<O>?
{ return if (input.isEmpty()) null else input.map
{ mapper.map(it) }
}
You need a different model for each DataSource
Let’s say we use a single model for both the network and the database:
@Entity(tableName = "Product")
data class ProductDTO(
@PrimaryKey
@ColumnInfo(name = "id")
@SerializedName("id") val id: String?,
@ColumnInfo(name = "name")
@SerializedName("name")
val name: String?,
@ColumnInfo(name = "nowPrice")
@SerializedName("nowPrice")
val nowPrice: Double?,
@ColumnInfo(name = "wasPrice")
@SerializedName("wasPrice")
val wasPrice: Double?)
At first, you may think this is way quicker than having 2 different models however do you see the risks of this approach?
If not I’ll list now a few for you:
- You may cache more than needed.
- Adding fields to the response will require Database migrations (unless you add an “@Ignore” annotation).
- All the fields that we cache that we shouldn’t send as Request Body will need a “@Transient” annotation.
- Unless we create new fields these must be of the same data type (we can’t, for example, parse a nowPrice string from a network response and cache a nowPrice double).
As you can see the final result is that this approach requires way more maintenance than having separate models.
You should cache only what you need
Let’s say we want to show a list of products stored in a remote catalog and for each product, we want to show the classic heart icon when this is in our local wishlist.
From this requirement, we understand that we need to:
- Fetch a list of products.
- Check our local storage to see if the products are in the local wishlist.
Our Domain Model will look like before with the addition of a field that says if the product is in the wishlist:
// Entitydata class Product(
val id: String,
val name: String,
val price: Price,
val isFavourite: Boolean)
{
// Value object
data class Price(
val nowPrice: Double,
val wasPrice: Double
) { companion object
{
val EMPTY = Price(0.0, 0.0)
} }}
Our Network Model will look just like before and the Database Model, well is not needed.
For the local Wishlist, we can just store the products ids in the SharedPreferences. We don’t need to complicate the logic for doing something so simple and deal with Database migrations.
And finally our Repository:
class ProductRepositoryImpl( private val productApiService: ProductApiService, private val productDataMapper: Mapper<DataProduct, Product>, private val productPreferences: ProductPreferences) : ProductRepository {
override fun getProducts(): Single<Result<List<Product>>> { return productApiService.getProducts().map { when(it) { is Result.Success -> Result.Success(mapProducts(it.value)) is Result.Failure -> Result.Failure<List<Product>>(it.throwable) } } }
private fun mapProducts(networkProductList: List<NetworkProduct>): List<Product> { return networkProductList.map { productDataMapper.map(DataProduct(it, productPreferences.isFavourite(it.id))) } } }
The dependencies used can be described as follows:
// A wrapper for handling failing requestssealed class Result<T> {
data class Success<T>(val value: T) : Result<T>()
data class Failure<T>(val throwable: Throwable) : Result<T>()
}
// A DataSource for the SharedPreferencesinterface ProductPreferences {
fun isFavourite(id: String?): Boolean
}
// A DataSource for the Remote DBinterface ProductApiService {
fun getProducts(): Single<Result<List<NetworkProduct>>>
fun getWishlist(productIds: List<String>): Single<Result<List<NetworkProduct>>> }
// A cluster of DTOs to be mapped into a Productdata class DataProduct( val networkProduct: NetworkProduct, val isFavourite: Boolean
)
Now, what if we want to get only the products related to our wishlist?
In that case, the implementation would be very similar:
class ProductRepositoryImpl(
private val productApiService:
ProductApiService,
private val productDataMapper: Mapper<DataProduct, Product>,
private val productPreferences: ProductPreferences) : ProductRepository
{
override fun getWishlist(): Single<Result<List<Product>>>
{ return productApiService.getWishlist(productPreferences.getFavourites()).map
{
when (it) {
is Result.Success -> Result.Success(mapWishlist(it.value))
is Result.Failure -> Result.Failure<List<Product>>(it.throwable) } } }
private fun mapWishlist(wishlist: List<NetworkProduct>): List<Product> { return wishlist.map
{ productDataMapper.map(DataProduct(it, true))
} } }
Last notes
I’ve used this pattern many times at a professional level and I see it now as a lifesaver, especially in big projects.
However, I’ve seen many times developers using it “because they have to” and not because they know the real advantages of it.
I hope you found this article interesting and useful.
To learn android course visit:android app development course



Comments
Post a Comment